Read/Write Split Overview
Read/Write split is the idea of separating queries to a database cluster to different servers, which operate in different roles, i.e. having multiple nodes that are used for reading only, while a master that replicates to them as a read/write node. While simple in concept, there are many issues that need to be considered when implementing, including:
- Replication Lag: The amount of time it takes for a write against the primary node to replicate to a read-only node;
- Transactional State: In a transaction, a read may lock records for later modification, so needs to be executed against the primary server instead;
- Stored Procedures: A stored procedure call may write to a table, which is not visible at the raw SQL layer;
- Triggers: A trigger may be attached to one table to write to another table, which is then read by the application;
- User Role: A reporting user may need to be unconditionally routed to a read-only node;
All these factors come together when implementing read/write split in order to decide one question--should a query be routed to the read-only server at this time, or to the read/write server? The more information that goes into this decision, the safer it is to push more queries to the read-only server.
Heimdall helps make this decision easier by tracking the replication lag between nodes, and using it's knowledge of the last write time to a table (from the cache engine) in order to make an intelligent decision on which servers should use a given node to insure that stale data is not read.
IMPORTANT For read/write split to work properly in a multi-node environment, cache invalidation events must be visible between nodes. This is typically done by setting up a cache engine, but can also be done by using the hdUsePGNotify option for Postgres servers (in source connection properties). A cache engine will need to be enabled for this to work, even with the hdUsePGNotify option.
Configuration
In order to enable read-write split the following is required:
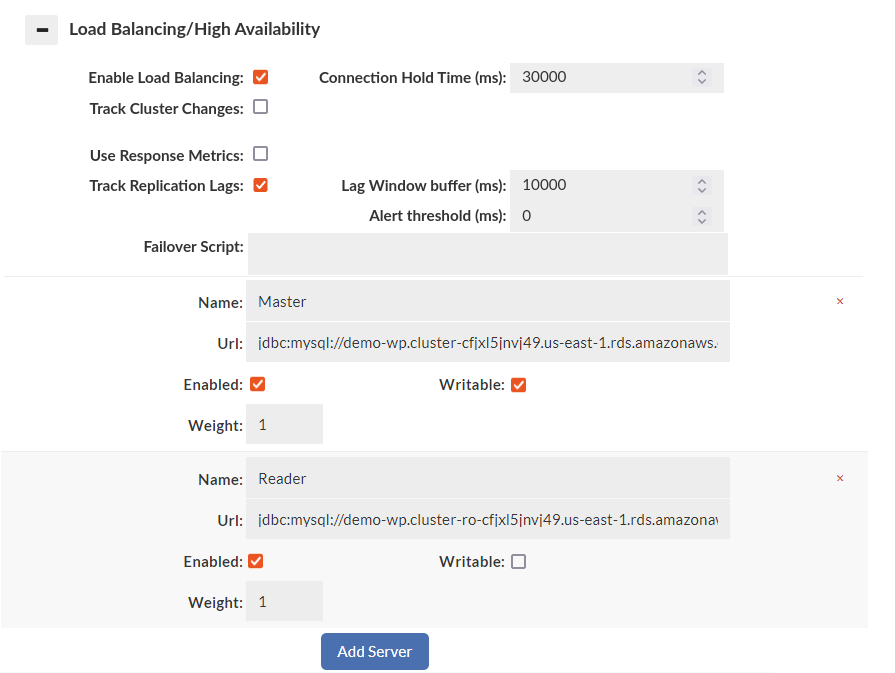
- Load balancing needs to be configured in the data source
- In the LB section at least two sources need to be defined. One with the writeable flag, and one without.
- If replication lag is to be accounted for one of or both the "Track Replication Lag" option needs to be checked, and/or the Lag window buffer set. Both can be used, or just one.
- In the rules tab associated with the VDB, a "reader eligible" rule needs to be defined that dictates what is eligible to be sent to the read-only nodes. Example configuration and status for tracking replication lag:
Data Source:
Rules:

Note: The lagignore option can be set to ignore lag for a particular set of queries. This is useful when a particular set of tables is not actually sensitive to lag, but may be reported as being written to often.
Status, showing the replication lag detected, and rate of queries against each role:
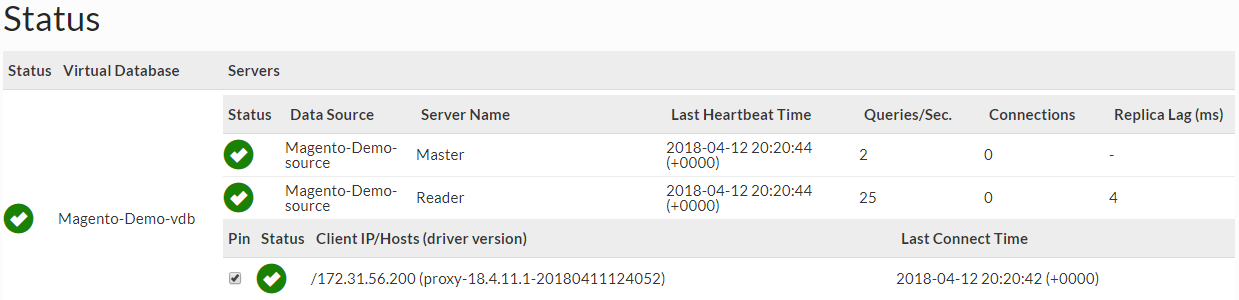
In the log section, the actual server selected can be observed for each query processed to validate that the correct actions are being taken, or the raw logs (if being generated) can be inspected.