Amazon AWS Specific Information
Please note--this section is organized in the form of a quick-start guide. If all the steps performed are done in-order, it will help to ensure success for an AWS deployment.
Typical Deployment
In most situations, customers go through two stages of deployment for Heimdall, a single server test deployment for POC installs and QA:
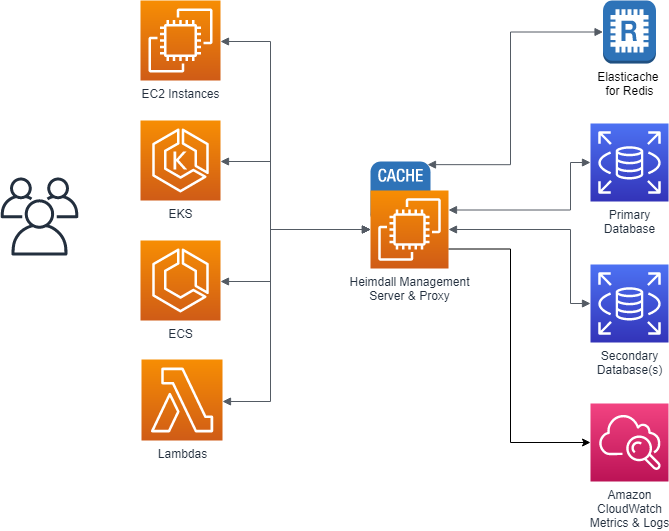
Here, Heimdall exists only on one server, and both the management server and the proxy exist together. Obviously, this results in a single point of failure, but this allows easy and fast proof of concept installs to occur. Once the idea of using Heimdall is validated, a more robust configuration is deployed:
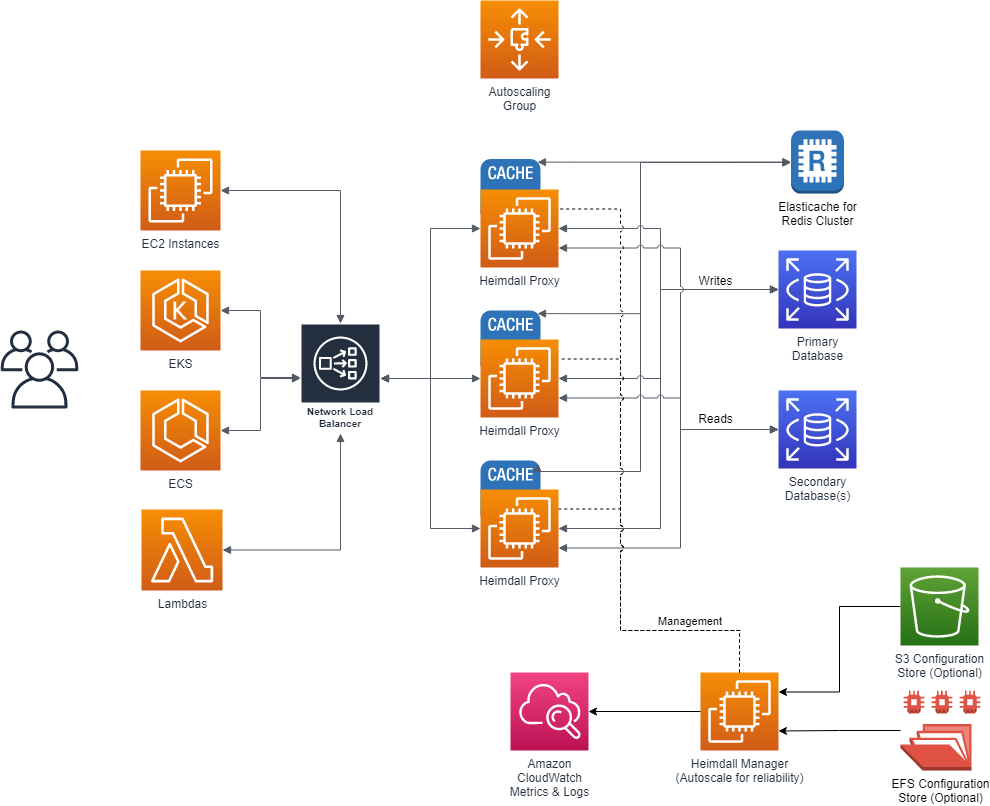
Here, the proxy nodes are deployed into one or more Availability zones (to match the applicaton server AZs) with autoscaling, and the central manager exists on it's own server. As the proxies operate as an independent data plane, failure of the management server is non-disruptive, so most customers choose to simply deploy a single management server. If a redundant management server is desired however, this can be done as well, with the obvious extra cost. In the single management server model, the management server can sit behind an autoscaling group, and keep it's configuration files on EFS, or pre-populate the configurations from S3, as desired.
RDS Support
Heimdall provides support for all MySQL, Postgres, and SQL Server RDS types, including Aurora and Aurora for MySQL, including all actively supported versions of those engines.
Creating an IAM Role
In order to simplify the configuration for Amazon Web Services, the system supports reading the RDS and Elasticache configuration directly. In order to use this feature, one must configure an IAM role with access to the appropriate rights, as shown, then the option for "AWS Configuration" will become available in the Wizard. Without the IAM credentials, a manual configuration is still possible.
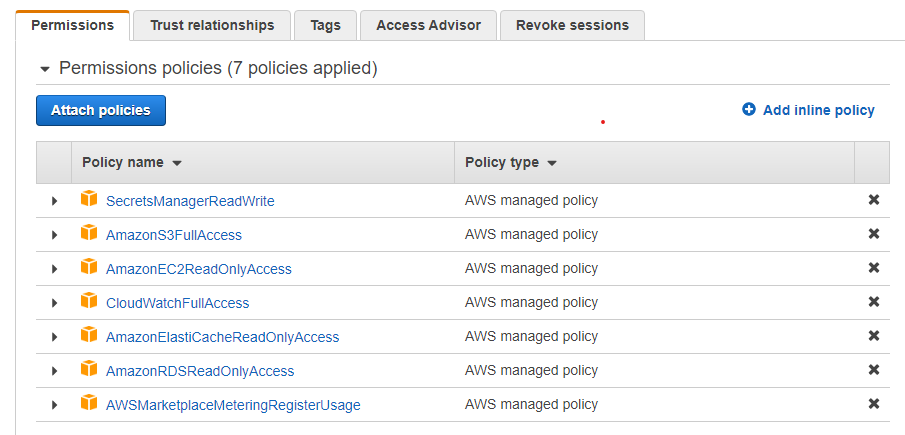
The permissions are for:
- AmazonEC2ReadOnlyAccess: To detect the local region being run in, and the security groups to validate proxy configurations
- AmazonRDSReadOnlyAccess: To populate database configurations and to enhance auto-reconfiguration of clusters on a configuration change or failover
- AmazonElastiCacheReadOnlyAccess: To populate the available caches
- CloudWatchFullAccess: When using cloudwatch monitoring, to build log groups and to report data (recommended, but not required)
- SecretsManagerReadWrite: If the hdSecretKey option is to be used, this permission enables the manager to pull and push configuration information into a secret.
Note: In a production environment, it's recommended to follow the principle of least privilege and grant only the specific permissions needed by the manager or the associated entity to perform their required tasks. This can be achieved by creating custom IAM policies with more granular permissions based on the specific resources needed and actions required. It is often easier to let Heimdall create resources such as secrets and cloudwatch log groups, and then lock down access to those needed vs. create them upfront. In order to simplify this, an automatically generated json file is provided for Heimdall use that includes all the possible api calls that may be needed at IAM Role Template. Please note--resource identification is templated as "changeme/*" as best practice is to limit roles to exactly what resources will be referenced. Please edit the template as needed for your environment.
For more information on IAM and IAM best practices please see Security best practices in IAM.
Note, for any given API access to work, in addition to the IAM role, the api endpoint needs to be accessible as well. To test if the api endpoints are accessible from a given client, you can use the following:
wget https://ec2.us-east-1.amazonaws.com/
wget https://rds.us-east-1.amazonaws.com/
wget https://elasticache.us-east-1.amazonaws.com/ (will return a 404, this is normal)
wget https://monitoring.us-east-1.amazonaws.com/ (will return a 404, this is normal)
wget https://secretsmanager.us-east-1.amazonaws.com/ (will return a 404, this is normal)
If these return anything other than a timeout, they are likely accessible. Otherwise, the api endpoint likely needs to be enabled in the VPC, due to routing restrictions.
Configuring an ElastiCache for Redis / Valkey Instance
If ElastiCache will be used, it is recommended that the instance be setup before configuring Heimdall, as this allows the ElastiCache configuration to be auto-detected. Heimdall supports Amazon ElastiCache using Redis-compatible engines, including Redis OSS and Valkey. When configuring ElastiCache, make sure at least two nodes are configured for redundancy if desired (clustered or not). For initial configuration on a POC, it is generally recommended that the following options be selected:
- Cluster mode enabled--this helps ensure proper behavior on a failover in a larger number of cases;
- Multi-AZ enabled;
- Size of m6g.large similar size instance. If load is low, then t4g.medium instances would be reasonable--the size can be adjusted if needed due to excessive bandwidth use after the initial install;
- At least one replica for redundancy;
- AZ selection should map to the availability zones that are expected to be used by the proxy layer and/or application servers;
- Security options such as enabling encryption in transit and access control is optional.
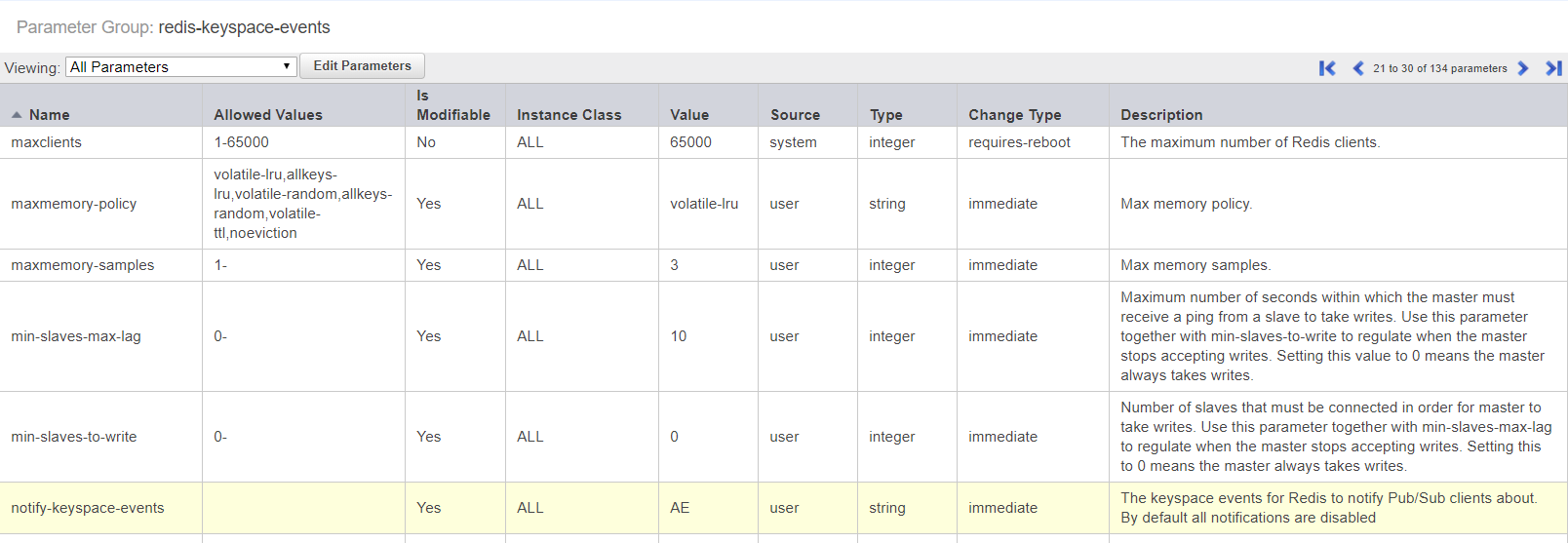
After configuring the ElastiCache for Redis or Valkey install, it is important to configure a parameter group, and set the parameter "notify-keyspace-events" to the value "AE". This will allow the system to track objects that are added and removed from the cache automatically, which helps prevent L2 cache misses. In other Redis types, this parameter can be set dynamically at runtime, but in ElastiCache, this can only be set via the parameter group. The configuration should appear as below:
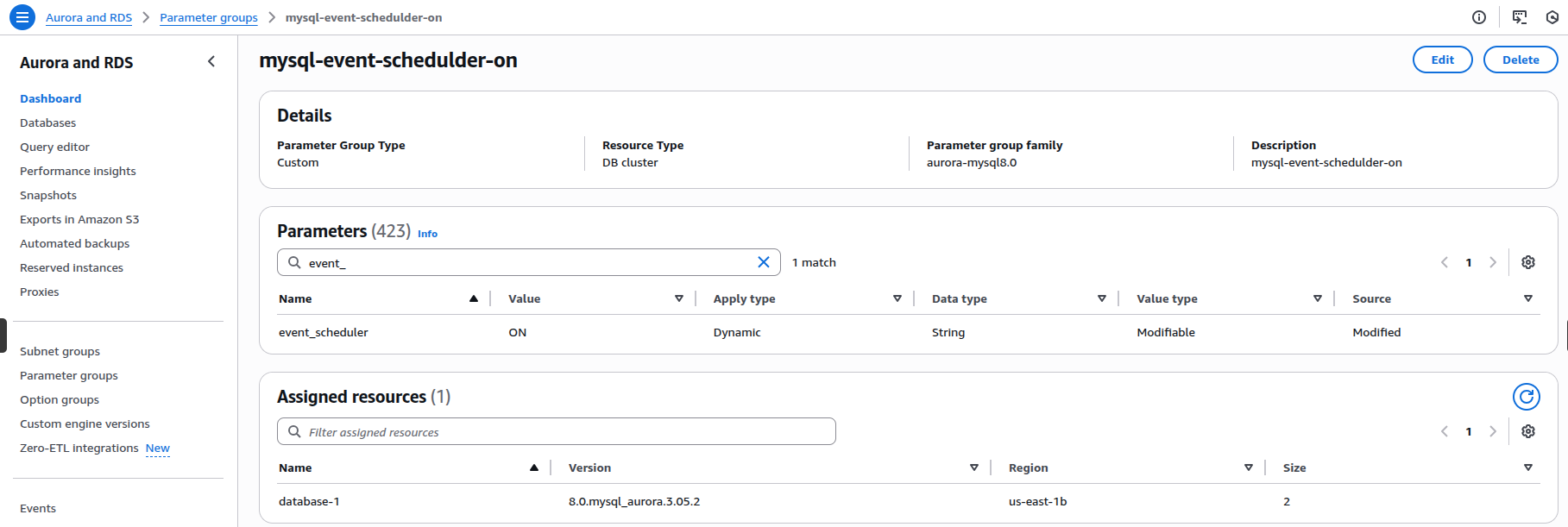
Configuring Event Scheduler in Aurora/RDS MySQL
To enable the event_scheduler, navigate to the Parameter Groups section in the RDS Console. Create a new parameter group (or edit an existing one), locate the event_scheduler parameter, and set its value to 'ON'. Then, assign this parameter group to your RDS/Aurora instance (a restart might be needed for the changes to take effect).
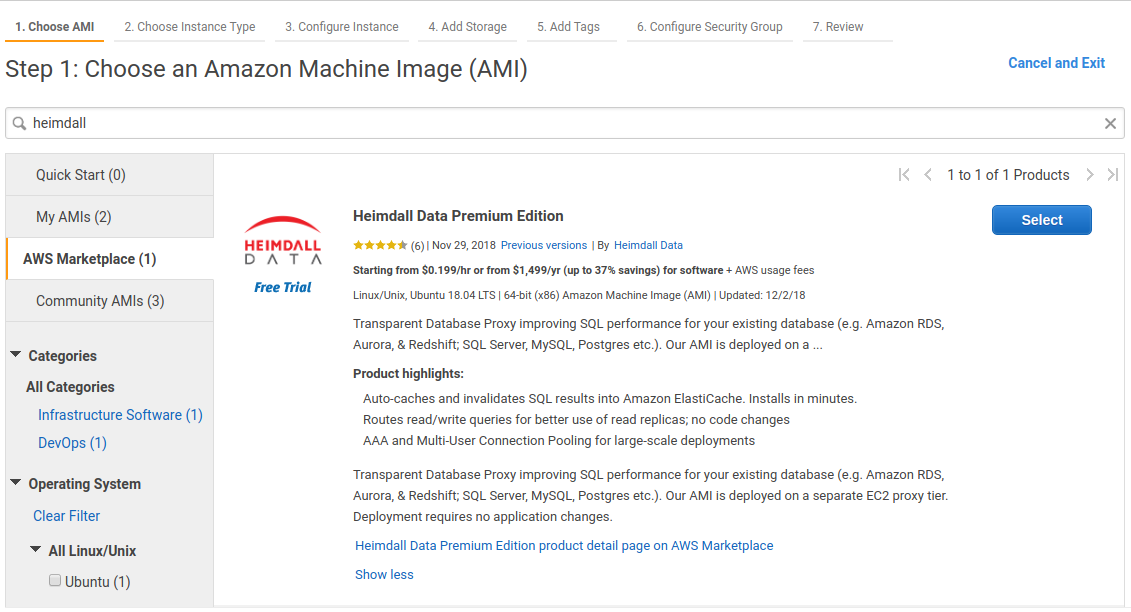
AWS Marketplace Install
Heimdall can be easily started using the AWS marketplace. During this startup, the image will download the newest release version of Heimdall. If the security groups are such that the download can not complete, then an older version of Heimdall will be used (from the instance creation time).
First, in the EC2, select launch instance, select the aws marketplace option on the left, and search for "Heimdall Standard Edition" or "Heimdall Enterprise Edition" with 24/7 support, then select:
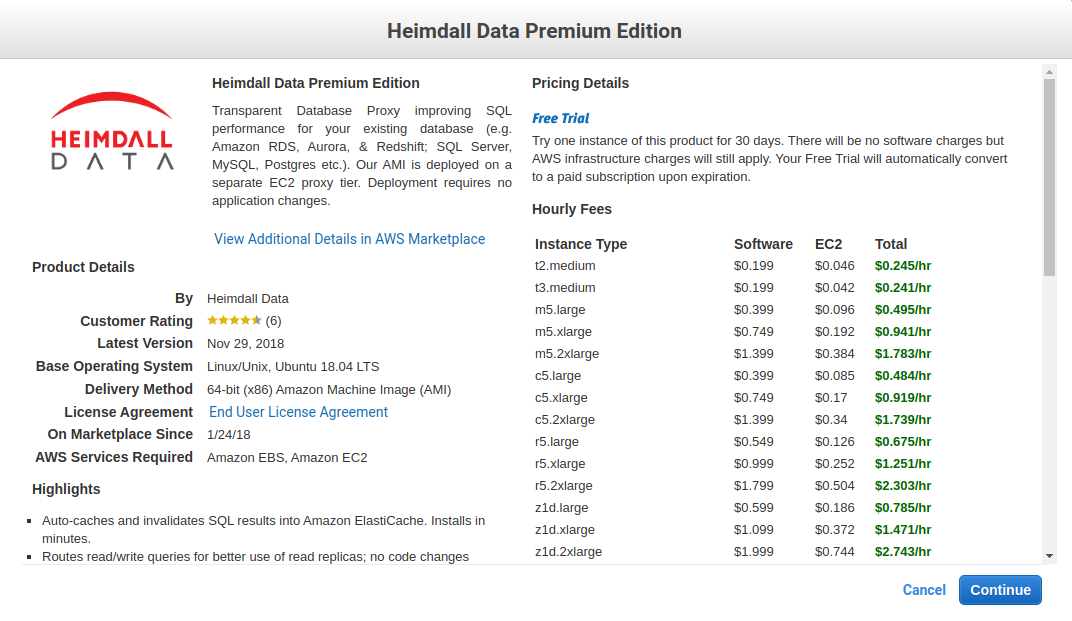
Then, continue with Heimdall:
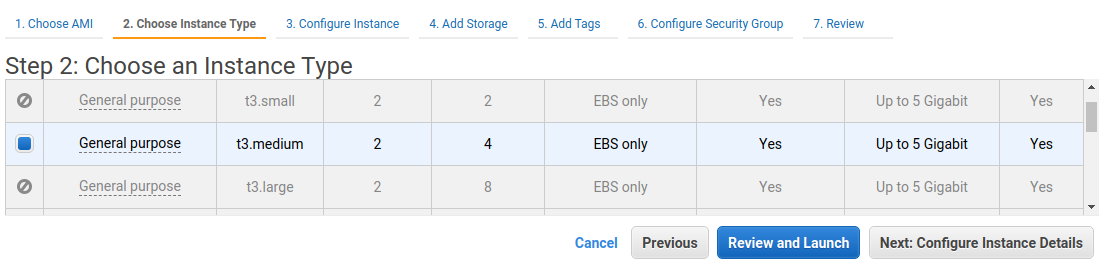
Select the desired instance types--The marketplace offering supports a variety of appropriate instances, with larger core counts supported in the Enterprise edition. Note on sizing: We generally recommend in initial core count for proxy capacity to be 1/4 that of the database behind Heimdall, so if the database has 8 cores, we would recommend starting with a 2 core proxy. In the event the cloud formation template was used, then you can split these cores across multiple proxies and use auto-scaling to size from there. In general, the c5 or Graviton 2 instances are recommended. For very high cache hit rates (over 90%), the c5n instance type may be appropriate, as the network bandwidth will be saturated before the CPU will be. Sizes can be adjusted once testing is complete and a better idea of the load ratio is understood.
Continue through the screens, ensuring that the security group configuration opens ports as needed for proxy ports (please update the source subnets to match your local networks, it is best practice to never open ports to the internet in general):
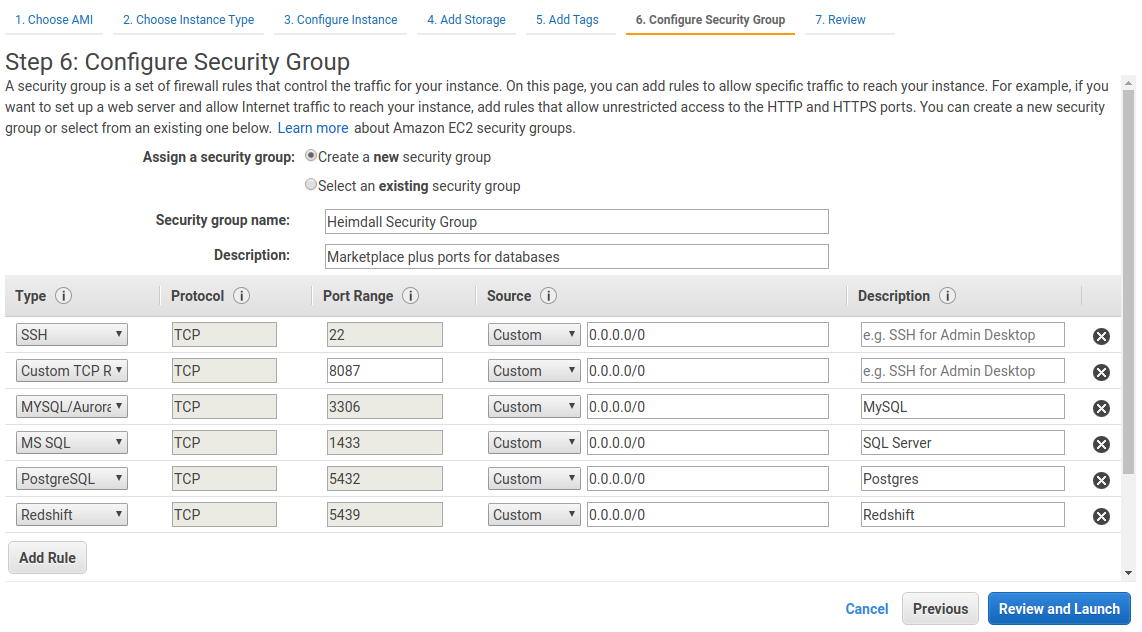
Finally, review and launch:
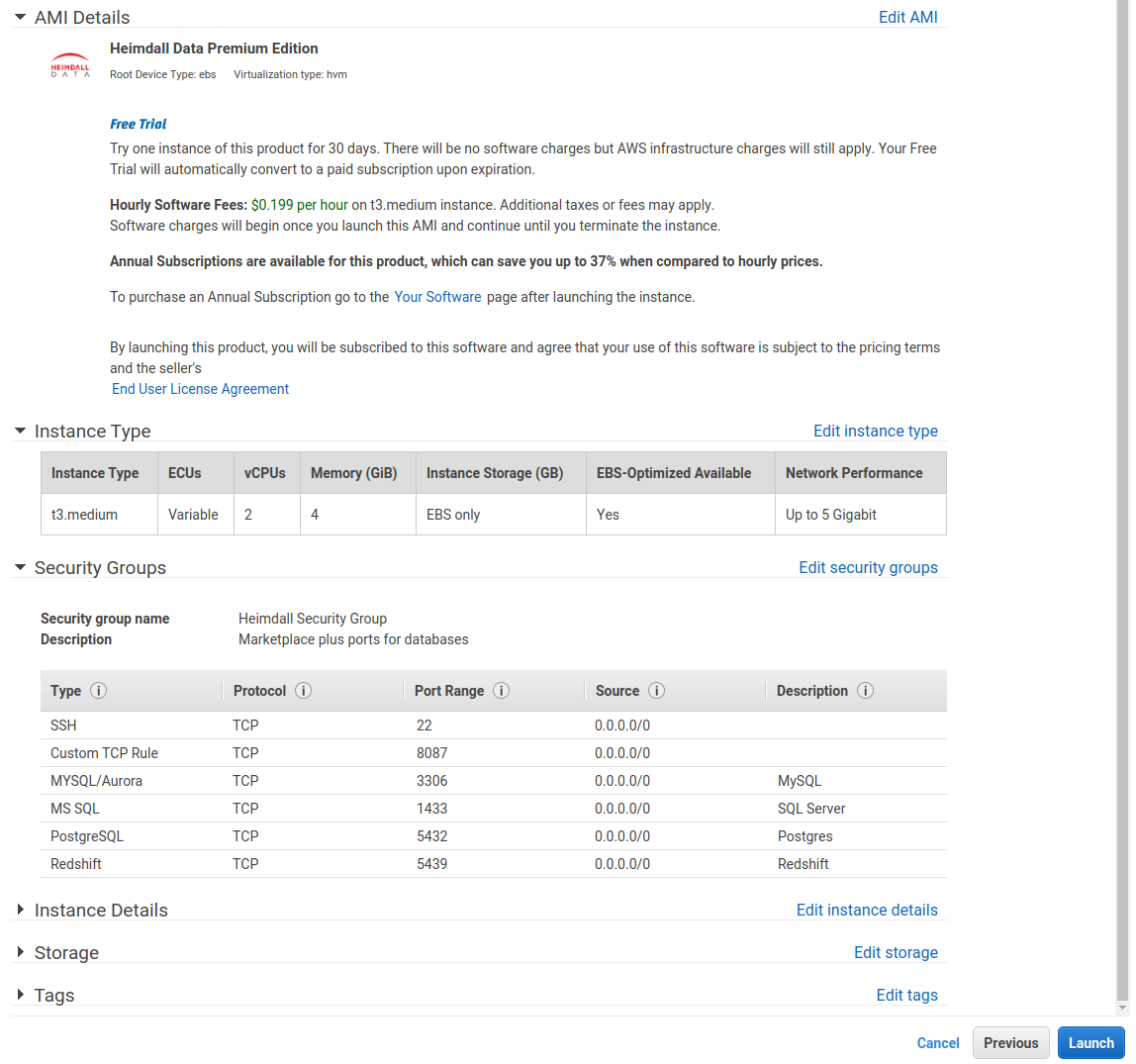
Next, with the EC2 instance online, you can bind the IAM Role created above to the EC2 instance, by right mouse-clicking on the instance, and under security, select modify IAM role. The following screen will allow you to select the role created. This enables autodetection of RDS and Elasticache resources, and other AWS integrations.
Once the instance is online and the IAM role is configured, connect to the instance on port 8087--there is a login help page providing instructions for the initial login. Please configure the instance using the wizard for the best results.. Nearly every manual configuration will have a fault, often resulting in support calls.
Advanced Marketplace Install
As Heimdall can run on multiple servers, at initialization, an instance can accept as user-data configuration options that will control how the instance runs, and if it should operate as a proxy or server (onl`y). When set to such a mode, the instance will attempt to tune itself for the role in question, i.e. use the entire instance's memory vs. allowing memory to be used. To provide these options, the user-data should be a script that generates a file "/etc/heimdall.conf". For more details see heimdall.conf configuration.
Please refer to AWS CloudFormation Template page for more information on using a template to create an autoscaling group, which automates the process of creating proxy-only instances, and provides failover resiliency as well.
CloudWatch Metrics and Logs
In each VDB, under logging, an option is available for AWS CloudWatch. If enabled and CloudWatch access is enabled in the system's IAM role, it will start logging a variety of metrics into CloudWatch under the "Heimdall" namespace, and the vdb logs will also be logged into CloudWatch. The metrics include:
- DB Query Rate
- DB Query Time
- Avg Response Time
- DB Read Percent
- DB Transaction Percent
- Cache Hit Percent
Please note that additional charges may be incurred due to metrics and logging, in particular if debug logs under high volume are logged into CloudWatch.
When using Heimdall on private IP ranges, please see https://docs.aws.amazon.com/AmazonCloudWatch/latest/logs/cloudwatch-logs-and-interface-VPC.html for more information to enable cloudwatch within the vpc.
TLS certificates for RDS
In the new builds starting in July 2021, the file rds-combined-ca-bundle.pem will be installed in /etc/ssl/certs and can be used to validate RDS CA certificates as appropriate and needed.
Aurora/RDS Load Balancing Behaviors
In an AWS RDS (including Aurora) environment, Heimdall has taken a flexible approach to allowing a cluster to be defined and configured. When used with RDS and the proper IAM role is attached to the management server(s), the primary URL hostname defined in the data source (outside of the LB) is used to identify a particular cluster. The cluster nodes are then probed in order to build the LB configuration. This definition is re-done at the initial cluster definition (if cluster tracking is enabled) every 30 seconds during normal processing and every 1 second when a node is in a "failure" mode, and also every time the data source configuration is committed.
When a cluster definition poll is done, the driver specified for the data source is used to create a new set of nodes. The nodes can be defined as "listener" (SQL Server only), "writer" node, "replica" for a read replica, or "reader" which includes both replicas and writers. The reader and writer URL's are then used to populate the nodes as appropriate based on the actual cluster state.
Please see the driver configuration page for information on each variable.
The goal of the Heimdall configuration is to bypass DNS resolution when possible for endpoints, which can slow down the failover process, while allowing the underlying drivers to support automatic detection and failover of the nodes that are acceptable for reader vs. writer roles. Through the default configurations provided by Heimdall, sub-second failovers can be achieved in most cases, and via the templates, custom configurations can be created to adjust the actual behavior desired.
For example, with the Postgres drivers, the default writerUrl template is:
jdbc:postgresql://${readers}/${database}?targetServerType=master
Here, the ${readers} is used, as the Postgres driver supports an ordered list, and the writer nodes will be included first in this list. With the targetServerType of master included, it will connect only to a master in the list, but on a failure, it will fail as quickly as possible to a new writer as soon as it is promoted. This allows the endpoint hostname resolution for Aurora to be bypassed, while providing the best possible availability.
And for the reader it is:
jdbc:postgresql://${readers}/${database}?targetServerType=preferSecondary&loadBalanceHosts=true&readOnly=true
Again, in this case, the driver's capability to load balance is being used to create a single pool of read connections, which will avoid using the writer node if possible.
An alternate writer URL could be used of:
jdbc:postgresql://${writer}/${database}
This wouldn't leverage the built-in failover capability, but would rely on Heimdall to detect a failure, and poll the AWS API's to find the new writer.
If each host in a number of readers is desired to have it's own node entry, along with graphs on the dashboard, and the write nodes should not be used for reading, the following alternate URL could be used:
jdbc:postgresql://${reader}/${database}?readOnly=true
This bypasses the postgres driver built-in LB capability, and will create a node for LB in Heimdall for each reader.
All built-in database types include a pre-defined set of reader and writer URL's except for Oracle, due to the complex nature of Oracle URL's for many environments. Older installs prior to this template function will have defaults included when updated to the code that supports this functionality.
Notes on behavior:
- ${writeEndpoint} and ${readEndpoint} can be used for Aurora definitions, and will point to the writer (primary) and reader endpoints as appropriate. This allows use of the AWS managed DNS targets if desired. DNS resolution on these will be cached for five seconds, and due to potential update timings, this could result in a connection intended for a writer to point to a reader instead. This is a side-effect of connection pooling, DNS caching, and the update timing of the DNS entry. This behavior can occur with other applications not using Heimdall as well.
- ${reader} will include the nodes that are expanded from ${writers}, but will set the weight of 1 vs. 10 for any pure reader node.
- ${readers} can be used in the writer URL definition to expand to the entire list of writers and readers for drivers that will use an ordered list to identify what is a writer and what is a reader. Other variables can only be used in the proper context, i.e. ${writer} for a writeUrl, or ${reader} for a readUrl.
- ${listener} is used only for SQL Server, and will resolve to the listener IP for a particular always-on cluster for the writerUrl, and will map to the writer instance in the cluster.
Things AWS doesn't tell you (or hides) that you need to know!
- Each EC2 instance type has a documented burstable bandwidth level, but it has an undocumented steady-state bandwidth level that often significantly lower than the burstable limit. One website has prepared a cheat-sheet that provides the numbers for many instance types.
- ELB including NLB (despite documentation to the contrary) may require pre-warming if you expect highly burstable traffic.
- RDS (but not Aurora) instances may get alerts of "Write query was sent to read-only server or transaction. Please see log for details." This error may be happening during your daily backup window, as the database may transition from writable to read-only during this window for a period of time. Aurora instances do not freeze this way due to the way they handle block IO.
AWS Policies
Heimdall Manager Recommended Least Privilege Policy
Template
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowExportHeimdallCertificates",
"Effect": "Allow",
"Action": [
"acm:ExportCertificate"
],
"Resource": "arn:${AWS::Partition}:acm:${AWS::Region}:${AWS::AccountId}:certificate/*",
"Condition": {
"StringEquals": {
"aws:ResourceTag/App": "heimdall"
}
}
},
{
"Sid": "AllowWriteLoginEventsToCloudTrail",
"Effect": "Allow",
"Action": [
"cloudtrail-data:PutAuditEvents"
],
"Resource": "arn:${AWS::Partition}:cloudtrail:${AWS::Region}:${AWS::AccountId}:channel/${ChannelId}"
},
{
"Sid": "AllowWritePortalEventsToCloudTrail",
"Effect": "Allow",
"Action": [
"cloudtrail-data:PutAuditEvents"
],
"Resource": "arn:${AWS::Partition}:cloudtrail:${AWS::Region}:${AWS::AccountId}:channel/${ChannelId}"
},
{
"Sid": "AllowDescribeElastiCacheClusters",
"Effect": "Allow",
"Action": [
"elasticache:DescribeCacheClusters"
],
"Resource": "arn:${AWS::Partition}:elasticache:${AWS::Region}:${AWS::AccountId}:cluster:${CacheClusterId}"
},
{
"Sid": "AllowReadIdentityStoreGroups",
"Effect": "Allow",
"Action": [
"identitystore:DescribeGroup"
],
"Resource": [
"arn:${AWS::Partition}:identitystore::${AWS::AccountId}:identitystore/${IdentityStoreId}",
"arn:${AWS::Partition}:identitystore:::group/*"
]
},
{
"Sid": "AllowWritePortalAuditLogs",
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:DescribeLogStreams",
"logs:PutLogEvents",
"logs:PutRetentionPolicy"
],
"Resource": [
"arn:${AWS::Partition}:logs:${AWS::Region}:${AWS::AccountId}:log-group:${PortalAuditLogGroupName}",
"arn:${AWS::Partition}:logs:${AWS::Region}:${AWS::AccountId}:log-group:${PortalAuditLogGroupName}:log-stream:*"
]
},
{
"Sid": "AllowWriteManagerLogs",
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:DescribeLogStreams",
"logs:PutLogEvents",
"logs:PutRetentionPolicy"
],
"Resource": [
"arn:${AWS::Partition}:logs:${AWS::Region}:${AWS::AccountId}:log-group:${ManagerLogGroupName}",
"arn:${AWS::Partition}:logs:${AWS::Region}:${AWS::AccountId}:log-group:${ManagerLogGroupName}:log-stream:*"
]
},
{
"Sid": "AllowDescribeAndPromoteRDS",
"Effect": "Allow",
"Action": [
"rds:DescribeDBClusters",
"rds:DescribeDBInstances",
"rds:DescribeGlobalClusters",
"rds:PromoteReadReplica"
],
"Resource": [
"arn:${AWS::Partition}:rds:${AWS::Region}:${AWS::AccountId}:cluster:${DbClusterInstanceName}",
"arn:${AWS::Partition}:rds:${AWS::Region}:${AWS::AccountId}:db:${DbInstanceName}",
"arn:${AWS::Partition}:rds::${AWS::AccountId}:global-cluster:${GlobalCluster}"
]
},
{
"Sid": "AllowManageHeimdallSecrets",
"Effect": "Allow",
"Action": [
"secretsmanager:GetSecretValue",
"secretsmanager:CreateSecret",
"secretsmanager:UpdateSecret"
],
"Resource": "arn:${AWS::Partition}:secretsmanager:${AWS::Region}:${AWS::AccountId}:secret:heimdall/*"
},
{
"Sid": "AllowPublishToSNSTopics",
"Effect": "Allow",
"Action": [
"sns:ListSubscriptionsByTopic",
"sns:Publish"
],
"Resource": [
"arn:${AWS::Partition}:sns:${AWS::Region}:${AWS::AccountId}:${NotificationTopicName#1}",
"arn:${AWS::Partition}:sns:${AWS::Region}:${AWS::AccountId}:${NotificationTopicName#2}",
"arn:${AWS::Partition}:sns:${AWS::Region}:${AWS::AccountId}:${NotificationTopicName#*}"
]
},
{
"Sid": "AllowReadS3HeimdallTemplates",
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::templates.heimdalldata.com/*",
"arn:aws:s3:::templates.heimdalldata.com"
]
},
{
"Sid": "AllowPutLogsIntoS3",
"Effect": "Allow",
"Action": [
"s3:PutObject"
],
"Resource": "arn:${AWS::Partition}:s3:::${CloudLogsBucketName}/*"
}
]
}
Example
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowExportHeimdallCertificates",
"Effect": "Allow",
"Action": [
"acm:ExportCertificate"
],
"Resource": "arn:*:acm:*:*:certificate/*",
"Condition": {
"StringEquals": {
"aws:ResourceTag/App": "heimdall"
}
}
},
{
"Sid": "AllowWriteLoginEventsToCloudTrail",
"Effect": "Allow",
"Action": [
"cloudtrail-data:PutAuditEvents"
],
"Resource": "arn:*:cloudtrail:*:*:channel/*"
},
{
"Sid": "AllowWritePortalEventsToCloudTrail",
"Effect": "Allow",
"Action": [
"cloudtrail-data:PutAuditEvents"
],
"Resource": "arn:*:cloudtrail:*:*:channel/*"
},
{
"Sid": "AllowDescribeElastiCacheClusters",
"Effect": "Allow",
"Action": [
"elasticache:DescribeCacheClusters"
],
"Resource": "arn:*:elasticache:*:*:cluster:*"
},
{
"Sid": "AllowReadIdentityStoreGroups",
"Effect": "Allow",
"Action": [
"identitystore:DescribeGroup"
],
"Resource": [
"arn:*:identitystore::*:identitystore/*",
"arn:*:identitystore:::group/*"
]
},
{
"Sid": "AllowWritePortalAuditLogs",
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:DescribeLogStreams",
"logs:PutLogEvents",
"logs:PutRetentionPolicy"
],
"Resource": [
"arn:*:logs:*:*:log-group:HEIMDALL-audit",
"arn:*:logs:*:*:log-group:HEIMDALL-audit:log-stream:*"
]
},
{
"Sid": "AllowWriteManagerLogs",
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:DescribeLogStreams",
"logs:PutLogEvents",
"logs:PutRetentionPolicy"
],
"Resource": [
"arn:*:logs:*:*:log-group:HEIMDALL-mgmt",
"arn:*:logs:*:*:log-group:HEIMDALL-mgmt:log-stream:*"
]
},
{
"Sid": "AllowDescribeAndPromoteRDS",
"Effect": "Allow",
"Action": [
"rds:DescribeDBClusters",
"rds:DescribeDBInstances",
"rds:DescribeGlobalClusters",
"rds:PromoteReadReplica"
],
"Resource": [
"arn:*:rds:*:*:cluster:*",
"arn:*:rds:*:*:db:*",
"arn:*:rds::*:global-cluster:*"
]
},
{
"Sid": "AllowManageHeimdallSecrets",
"Effect": "Allow",
"Action": [
"secretsmanager:GetSecretValue",
"secretsmanager:CreateSecret",
"secretsmanager:UpdateSecret"
],
"Resource": "arn:*:secretsmanager:*:*:secret:heimdall/*"
},
{
"Sid": "AllowPublishToSNSTopics",
"Effect": "Allow",
"Action": [
"sns:ListSubscriptionsByTopic",
"sns:Publish"
],
"Resource": "arn:*:sns:*:*:*"
},
{
"Sid": "AllowReadS3HeimdallTemplates",
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::templates.heimdalldata.com/*",
"arn:aws:s3:::templates.heimdalldata.com"
]
},
{
"Sid": "AllowPutLogsIntoS3",
"Effect": "Allow",
"Action": [
"s3:PutObject"
],
"Resource": "arn:*:s3:::*/*"
}
]
}
Heimdall Proxy Recommended Least Privilege Policy
Template
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowDescribeAndExportHeimdallCertificates",
"Effect": "Allow",
"Action": [
"acm:DescribeCertificate",
"acm:ExportCertificate"
],
"Resource": "arn:${AWS::Partition}:acm:${AWS::Region}:${AWS::AccountId}:certificate/*",
"Condition": {
"StringEquals": {
"aws:ResourceTag/App": "heimdall"
}
}
},
{
"Sid": "AllowPutHeimdallProxyMetrics",
"Effect": "Allow",
"Action": [
"cloudwatch:PutMetricData"
],
"Resource": "*",
"Condition": {
"StringEquals": {
"cloudwatch:namespace": "${ProxyLogGroupName}-proxy"
}
}
},
{
"Sid": "AllowDescribeEC2Instances",
"Effect": "Allow",
"Action": [
"ec2:DescribeInstances"
],
"Resource": "*"
},
{
"Sid": "AllowWriteProxyLogs",
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:DescribeLogStreams",
"logs:PutLogEvents",
"logs:PutRetentionPolicy"
],
"Resource": [
"arn:${AWS::Partition}:logs:${AWS::Region}:${AWS::AccountId}:log-group:${ProxyLogGroupName}",
"arn:${AWS::Partition}:logs:${AWS::Region}:${AWS::AccountId}:log-group:${ProxyLogGroupName}:log-stream:*"
]
},
{
"Sid": "AllowReadHeimdallSecrets",
"Effect": "Allow",
"Action": [
"secretsmanager:GetSecretValue"
],
"Resource": "arn:${AWS::Partition}:secretsmanager:${AWS::Region}:${AWS::AccountId}:secret:heimdall/*"
}
]
}
Example
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowDescribeAndExportHeimdallCertificates",
"Effect": "Allow",
"Action": [
"acm:DescribeCertificate",
"acm:ExportCertificate"
],
"Resource": "arn:*:acm:*:*:certificate/*",
"Condition": {
"StringEquals": {
"aws:ResourceTag/App": "heimdall"
}
}
},
{
"Sid": "AllowPutHeimdallProxyMetrics",
"Effect": "Allow",
"Action": [
"cloudwatch:PutMetricData"
],
"Resource": "*",
"Condition": {
"StringEquals": {
"cloudwatch:namespace": "HEIMDALL-proxy"
}
}
},
{
"Sid": "AllowDescribeEC2Instances",
"Effect": "Allow",
"Action": [
"ec2:DescribeInstances"
],
"Resource": "*"
},
{
"Sid": "AllowWriteProxyLogs",
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:DescribeLogStreams",
"logs:PutLogEvents",
"logs:PutRetentionPolicy"
],
"Resource": [
"arn:*:logs:*:*:log-group:HEIMDALL",
"arn:*:logs:*:*:log-group:HEIMDALL:log-stream:*"
]
},
{
"Sid": "AllowReadHeimdallSecrets",
"Effect": "Allow",
"Action": [
"secretsmanager:GetSecretValue"
],
"Resource": "arn:*:secretsmanager:*:*:secret:heimdall/*"
}
]
}