Caching Architecture
Heimdall operates via a two-layer cache system. The first layer (L1) is an in-heap cache, the size of which is controlled by the cache size in the VDB settings. The second layer (L2) may either not exist (local cache only), or will leverage any one of the supported cache engines, to provide a distributed cache between nodes.
For caching to be active, the following conditions must apply:
- The VDB defines a base cache configuration
- A rule-set is attached to the vdb
- The rule-set defines one or more cache rules (please see the rules configuration section for the list of cache options)
- the query meets some minimal qualification for caching based on built-in logic, including size limits, etc.
Caching Logic Flow
The (simplified) order of logic processing is as follows:
- Request processing
- Parse query for tables (this can be displayed with the printTables property on a rule)
- Rule processing:
- if (table property) Add to the table list for the query
- if (cache) set cache ttl to query
- if (nocache) unset any cache TTL and flag to not cache at all
- After processing the rule, if a cache TTL is above 0 and caching is set
- Create a 64 bit hash of the query and all parameters
- Perform lookup on L1 cache with the hash
- If no L1 cache hit, then check if L2 cache has the object
- If a result is returned from the L1 or L2 (grid) cache
- Check if the result has a creation time later than the last write time for any associated tables, if so delete object from the cache
- Return the result to the client
- If no result has been returned, retrieve from the database
- If the query is not cacheable, check if it is an update
- If an update, then trigger an invalidation message into the L2 cache pub/sub interface for associated tables
- After pub/sub message is transmitted, forward the query to the database
- On result processing (from the database)
- If the query was flagged with a TTL, create a cache object
- If in proxy mode, return result to the proxy module to serialize
- If in JDBC mode, attach result to the cache object
- Trigger the log result
- After the result-set is closed at the application level
- queue the result for an ingestion thread
- Place the cache object (and all metadata) into the L1 cache
- If necessary, serialize the result for L2 caching and push into the L2 cache
Caching has two fundamental modes of operation, depending on if Heimdall is in proxy mode or operating as a JDBC driver. In proxy mode, the cached object will be the serialized version of the result-set that is pushed on the wire, in order to reduce the overhead of generating a response for following cache hits. The serialized data is also stored in the L2 cache in this same form, as the result is sent to the client the first time, this reduces the overhead of interacting with all layers of the cache. This process also accounts for variables such as character set that may result in different resultset representations depending on the state of the connection to the database.
When in JDBC mode, the local L1 cache stores result-sets in Java object form on the local heap, in order to provide the results in the form the application will use them. When storing into the L2 cache, the results will be serialized into a format that is compatible with all cache engines supported, and only pulled and de-serialized when necessary.
Caching will trigger the query to generate a 64 bit hash of the query, and lookup in the cache index if there is a matching response. In the event there is, request processing is terminated, and the response is processed to the caller. On a cache miss, the processing continues, and on the response side of processing, the response will be stored in the cache store for later use, with a time to live based on the cache rule setting.
When an object is cached, the query that generated it will be hashed to a 64 bit query hash, including all parameters necessary to generate uniqueness (by default vdb, catalog, user). The object will then be pushed into the L1 and L2 cache, if present. Our cache logic is designed to do cache key synchronization as well, so any object pushed into the L2 cache will be visible to all other nodes. The benefit to this is that we will rarely if ever have a cache miss against the L2 cache. As the L2 caches are generally on remote nodes, this minimizes the overhead of caching, and prevents a double round-trip on a cache miss.
In the event that due to a previous cache configuration, an object was cached that would now no longer be cached, due to the order of operations, the old “stale” object will be thrown out after being pulled from the cache. This applies to table exclusion rules, or TTL changes. As such, unlike most systems, a change to the cache rules will not require a purge of the cache to prevent invalid data from being returned.
Each cache object is tagged with the tables the query was associated with, and internally, all tables are tracked with a last modified time, in milliseconds. On a cache lookup, if the object was created prior to the last modified time of any table it is associated with, then the object is flushed from the cache, and repopulated. This helps insure that even if cache policies are changing, the current policies ttl limit will be honored, even if the policy is created or changed after the object enters the cache. Last modified data can come from any one of several sources:
- A DML was observed on the table directly by the driver
- An invalidation record with a newer last modified time was pulled from the grid cache
- A last modified time was pulled from the database via trigger notification
- The first two of these don’t require any additional configuration. The third requires some configuration to setup and configure the database to support this. Currently, sample trigger configurations are available for MySQL and MS-SQL, and can be developed as needed for other databases. Please contact support for assistance with this feature.
Table Caching provides a refinement to any cache policy in order to override a TTL of 0, or reduce the cache TTL on a match. In the case of a cache value of TTL, table cache entries may override the base TTL if and only if all tables have a positive ttl specified. If a table cache entry specifies a ttl of zero, and the table is present in a query, the query will not be cached. Regex patterns do not apply on a table cache, nor are they ignored, even if the “ignore” action is used.
Stored Procedures, Views and Triggers
When using any query that can't be directly parsed, it is possible to still properly enable caching and invalidation. There are a few critical pieces that need to be configured however:
- When tables being written to can't be parsed, add a "table" property, then the fully qualified name of the table, i.e. magento.log_table, and set the property "update" to true, if necessary. On a write, only the table(s) being written to need to be associated with the query, as any reads will be done server-side, and will not come from the cache.
- When tables are being read that can't be parsed, like with a write, use the "table" property to specify the fully qualified table names being read from, and set the property "update" to false. This will insure that writes against the read tables will invalidate the queries being read from.
Example:
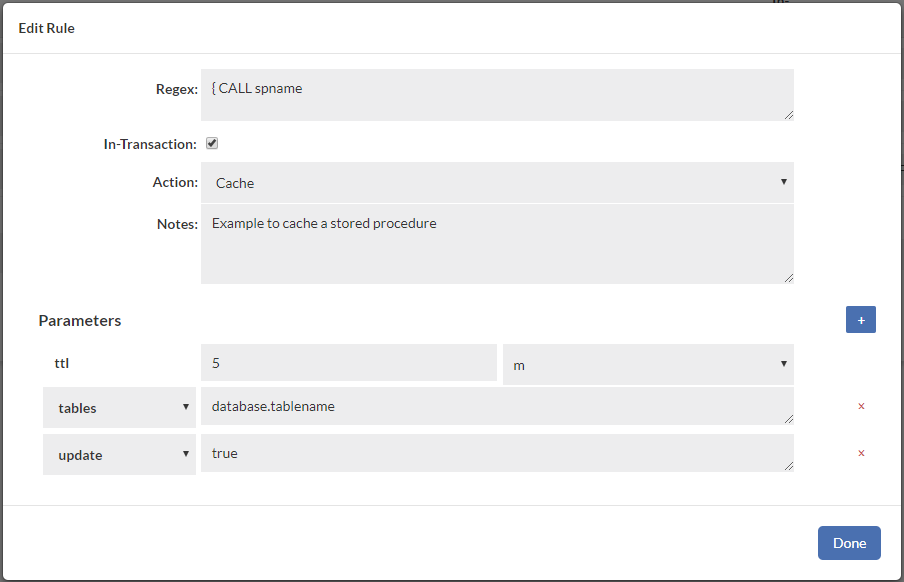
In the case of views, simply use the tables:{tablename} syntax to match the view name, then attach the tables that are associated with it. Nested tables can be handled with this as well, as long as the order is correct, i.e. a view using another view is defined before the view it uses. This way, you attach each view's tables to a growing list of tables.
Routing Read-Only Stored Procedures to Replicas
By default, the Heimdall routes all MySQL stored procedure (CALL spName) statements to the primary (writer) node to ensure data integrity — even if the procedures contain only read operations. However, you can optimize performance by explicitly routing read-only stored procedures to replicas using Heimdall Query Rules.
To route a read-only procedure to a replica, create a Heimdall Query Rule with the following configuration:
- Action:
Reader Eligible - Regex: Match the exact stored procedure call (e.g.,
(?i)^CALL spName) - tables: Specify the table(s) read by the procedure (e.g.,
schema.tableName) - update:
false(indicates no data modification) - unconditional:
true(forces the rule to apply regardless of internal conditions) - lagignore:
false(ensures replication lag is considered)
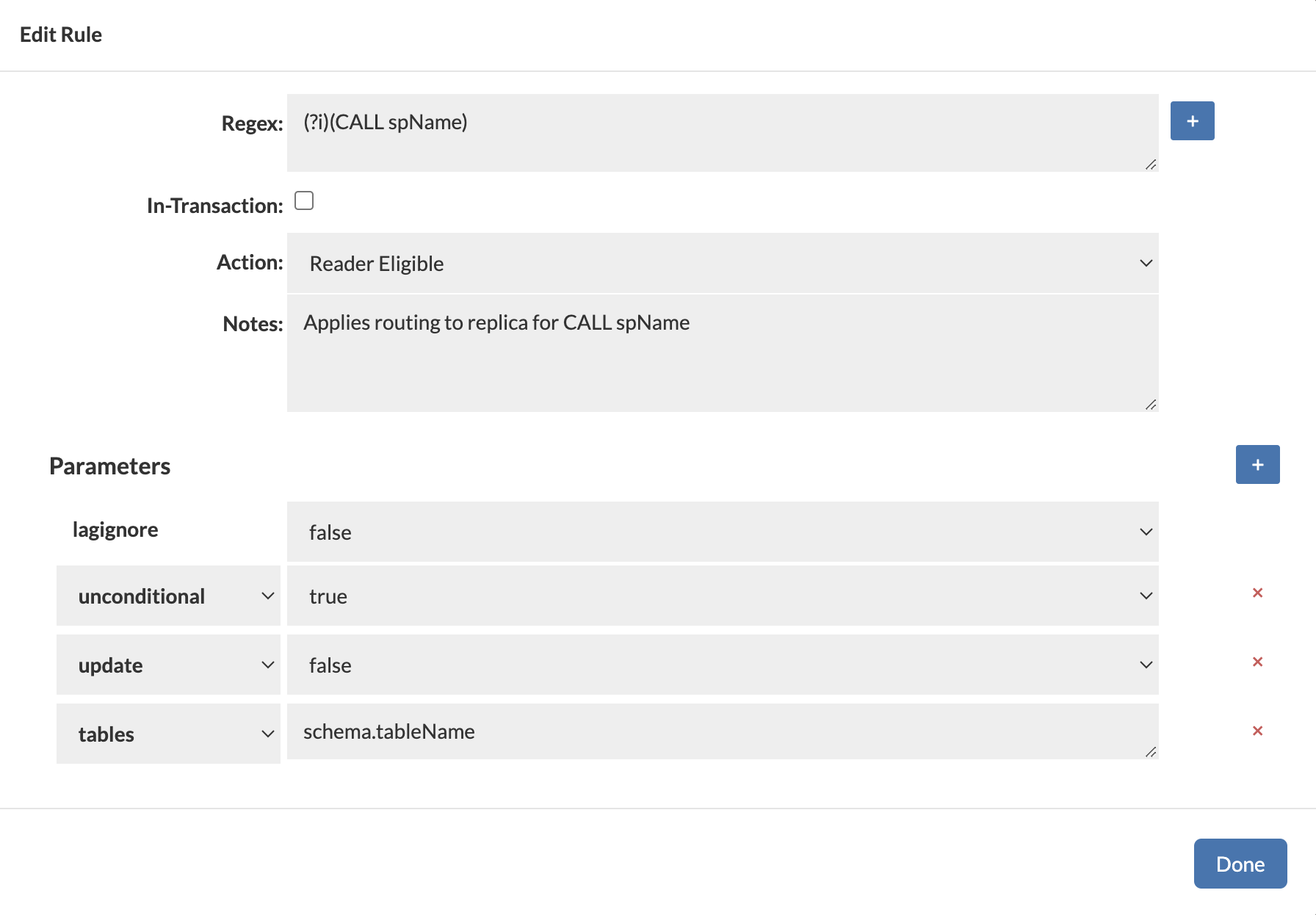
Example Configuration
Regex: (?i)^CALL spName
Action: Reader Eligible
tables: schema.tableName
update: false
unconditional: true
lagignore: false
The unconditional=true parameter is useful when Heimdall cannot clearly understand or analyze complex stored procedures. By setting this parameter, you instruct Heimdall to rely on your rule configuration explicitly, enabling safe routing of queries to read replicas.
Below is a screenshot of a configured Query Rule that routes a read-only stored procedure (CALL spName) to a read replica using unconditional=true
Repopulation
When the heimdall proxy or driver is restarted, if connected to an L2 cache, it will request all the current keys from the L2 cache. This will be used to determine what objects (as they are accessed) can be pulled from the l2 cache layer. If not present, then repopulation will be done from the database itself. No cache data is stored on the disk of the proxy nodes by Heimdall, and all cache objects can be considered "in-flight" or transient.
Invalidation
When a DML operation is detected by Heimdall, and a cache engine is configured, it will use the pub-sub interface of the cache engine in order to exchange information on what tables were written to and when. This is shared across nodes, so that each node knows when other nodes perform a write. In addition, some additional logic is used to reduce the number of invalidation messages:
- If less than 95% of queries are flagged as reads, then a table is deemed non-cachable, and any writes to the table should also trigger a "super-invalidation" to other nodes
- If more than 100 invalidations a second are triggered, then trigger a "super-invalidation" on tables being written to as well
A super-invalidation is a message that when sent to all the other nodes triggers non-cachability of the referenced table for two seconds.
To override invalidation of a table as a result of a DML, the property "invalidate" can be set to false to prevent any eviction action. This will not prevent caching of the object.
To explicitly control if a particular query is treated as an update, the property "update" can be set to true. This will further trigger invalidations against associated tables if parsed.
One final option to control invalidation is to use the "olderthan" property, which can be set to a negative value. In this case, invalidations last into the future, so a write against a table may prevent cached results for a period of time after the write.
Configuring Trigger Based Invalidation
In order to support out-of-band data ingestion into the database, a data source can be configured for "Trigger based invalidation". There are several options available on the data source for this configuration:
- dbTriggerTracking: set to true if this feature is to be enabled
- dbTimeMs: A query to retrieve the current time in MS on the database, to insure timestamps are synchronized
- dbChanges: A query to retrieve a timestamp (as a long) and table name (as a string), for the last invalidation time of that table.
The dbTimeMs call for example defaults to the value of "SELECT heimdall.get_time_ms()", usable on MySQL without any changes. The dbChanges call defaults to {CALL heimdall.changes(@ts)}. This can be a stored procedure. The string "@ts" will be replaced automatically with the last modification (per the DB time) that has been observed, so can be used to pull only the tables that have been modified since the last invalidation observed. The table name returned needs to be fully qualified, as observed with the "printTables" option for the rules, as this is the table name we will be comparing for invalidation purposes.
Note 1: As the trigger table queries are performed as part of LB health checking, the load balancing feature must be active to use this feature Note 2: Please see the database specific documentation for examples on how to configure the trigger based invalidation on the database side
API Based Invalidation
When using the healthcheck-port option (see VDB Properties), an additional feature is enabled, that of HTTP based eviction. To use this, a call can be made on the healthcheck port such as "/invalidate?vdb=&table=". This will trigger the proxy to process an invalidation as if a write had been detected to the table. In a distributed cache scenario, this is propogated to other nodes as well. Debug logging will provide additional verification that the invalidation has occurred. The table name of "all" can be used to clear all tables associated with the VDB on a given proxy node (this is not propogated across nodes however). Table names can also be regular expressions. When a table is invalidated via regular expressions, the tablename will be returned as the response body in a CSV list. Note: If a table has never been invalidated, it will be considered to have a last write time of 0 implicitly, so won't need to be invalidated, and will not show up in the list of tables invalidated.
Healthcheck-port can also be secured with an authorization token if Enable Token Authorization is checked. A field with a generated token will appear where the token can be changed manually or randomly generated by using the “generate new token” button. If a user wants to perform an HTTP call with enabled authorization they must add a token to request parameters.
Example debug logs when using this feature:
curl "http://localhost:8081/invalidate?vdb=Vevo-demo-vdb&table=test&token=securityToken"
[2018-12-04 19:28:49,060] 2018-12-04 19:28:49,060 308879 [INFO] [nioEventLoopGroup-9-1] Cache: Invalidated: test vdb: Vevo-demo-vdb time: 1543951729070
[2018-12-04 19:28:49,060] 2018-12-04 19:28:49,060 308879 [INFO] [nioEventLoopGroup-9-1] Issuing invalidation on table: test at: 1543951729070
Note: Always make sure to specify the table name as it shows as a result of the printTables command or from the expanded query view in the analytics tab, otherwise the invalidation will not be successful.
Auto-Refresh
In many situations, particularly for Analytical and Dashboarding workloads, a small but repetitive set of queries are issued against a database that is only periodically refreshed. The queries against the data-set may be very expensive and time consuming, and if issued only when someone wants to view a report, may result in a long lag before the report is rendered. This feature is for this use-case.
The way auto-refresh works is that first, heimdall will cache a query, typically for an extended TTL, be it one day or longer. Next, when a data load is done, the table the invalidation is cached against. This invalidation will trigger Heimdall to inspect all the last X queries it has processed, and will re-execute the queries, in order to re-populate the cache with the fresh data. This refresh will be done from most frequently used queries to least frequently used in order to make data that is most likely to be needed available as soon as possible.
The net result of this is that immediately after a data load and invalidation, the cache is refreshed, and reports can be rendered quickly when needed without queries being processed on the database.
To enable auto-refresh, in the VDB, set the vdb property "trackQueryDistributionCount" to the number of the most recent queries to track (say 10,000) and then in your cache rules you can set the property autoRefresh. The following conditions must be met for a refresh to occur:
- The query tracker must have at least two instances of the query being issued. One is not sufficient. If the query tracker is under-sized, then this will impact refresh capabilities.
- The query must be in the cache at the time of the invalidation;
- One or more tables associated with the cached query must be invalidate.
Queries will be refreshed based on the most frequently accessed query to least frequently, and refresh queries themselves will not be tracked by the query tracker.
Note: Auto-refresh is not yet functional with the SQL Server proxy
Debugging
One of the most common issues with caching is that the tables extracted from the query or otherwise assigned to a query via a rule do not match between queries and updates. There are a variety of reasons why this can be, including the use of the Postgres search path to search multiple schemas, stored procedures, or invisible updates due to triggers. The easiest way to diagnose this is to create rules that match the update query and the read query, then add the "printTables" property, with the value of true. This will result in log entries such as:
[2018-12-06 15:17:43,924] ip-172-31-14-81.ec2.internal: Query: SELECT ? FROM ir_module_module WHERE name=? AND latest_version=?~3~\"1\"~\"'base'\"~\"'11.0.1.3'\"~ tables: [odoo.public.ir_module_module] isUpdate: false
The table name(s) listed in the tables field must match exactly for invalidation to operate properly.
Additionally, when objects are configured for caching, but are not eligible for caching for some reason, in general, the debug logs will provide additional information on why this is the case. One case that comes up with SQL Server stored procedures often is that they are returning more than one result set. This case is not currently supported by Heimdall.
In order to debug the auto-refresh tracking, the command "heimdall querytracker" can be issued. A table name can be issued following this to narrow down the queries tracked against a particular table.